今回は緩めにセグメンテーションのやってみた記事です。
とりあえず今までSSDでの物体検出やGANを用いた画像の異常検知やらをやってみまして,そろそろ次のタスクをやろうなかーと思いまして,今回はちゃんとした(?)セグメンテーションにしてみようと思います。
「ちゃんとした」と銘打ったのは,2クラスのセグメンテーションはやったことがあるんですけど,3クラス以上のセグメンテーションらしいセグメンテーションはやったことがないなーという感じだったので,一度は勉強のためにやっておこうというモチベーションです。
参考:過去記事
▼分類
【PyTorch】MNISTのサンプルを動かしてみた
▼物体検出
SSD (Single Shot MultiBox Detector) による物体検出
【物体検出】SSD300とSSD512の比較
▼セグメンテーション
【Keras+TensorFlow】Deep Learningで顔検出をしてみた
【Keras+TensorFlow】Deep Learningでテロップ位置を検出してみた
▼回帰
【海洋物理】Deep Learningで海面高度/水温から鉛直プロファイルを推定してみた
セグメンテーションのアルゴリズム
緩めの記事なのでざっくり行きます。物体検出とはやや違ってセグメンテーションには「セグメンテーションといえばこれでしょ!」というようなアルゴリズムはあまりないような気がします。一応インスタンスセグメンテーションでMask R-CNNあたりが有名かなとは思いますが。
で,セグメンテーションには大きくセマンティックセグメンテーションとインスタンスセグメンテーションがありますが,その違いはざっくりいうと「同じクラスかつ別の個体を区別して認識するかどうか」です。
例えばコップが2つ写っている画像の場合に,
- 各ピクセルがコップなのか否かを認識→セマンティック
- コップのピクセルの場合にコップ1なのかコップ2なのかを識別→インスタンス
というような違いがあります。
今回使ったアルゴリズム
上述の通りセグメンテーションの中にも複数のアルゴリズムがある訳ですが,今回はPSPNet : Pyramid Scene Parsing Networkを使用することにします。
最近仕事でSOTAないしSOTA近辺の比較的新しいアルゴリズムの検証をしてみることが多いのですが,最近の論文はあまり再現性がなかったりハイパーパラメータのチューニングがかなりシビアだったりと,あまりやってみる価値が無いようなものが多いため,比較的古くて安定したアルゴリズムであるPSPNetを使用することにしました。
PSPNetのざっくりした説明
細かい説明は論文を読んで頂くのが良いと思いますが,ざっくりとはこんな構造になっています。
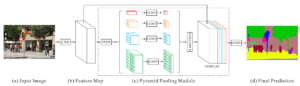
Fig 3. Pyramid Scene Parsing Network
まずFeature MapのところはResNetやら何やらの適当なBackboneを用意します。そしてそこの出力をpoolでサイズを変換してやった上でconv層→concatenate→conv層という感じで接続していきます。
この図ではPool処理がひとつだけのように見えますが,実際は各サイズごとにPoolが存在しているため,計4つのPool処理が存在しています。
そして,最後の予測のところは各ピクセルごとにクラス数分のチャネルが存在していて,各チャネルが各クラスに対応しています。要するにピクセルごとにクラス分類をやっているという形式になっています。
あともうひとつの特徴的な点としてAuxiliary Lossがあります。
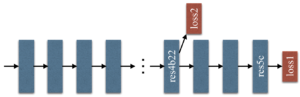
考え方自体はシンプルで「Backboneの途中出力を用いて,最終出力と同じようにLossを計算する」という処理です。ネットワークが比較的深い時などに度々使われる手法ですが,途中出力から誤差逆伝播で学習することで深い層(=入力側に近い層)までちゃんと学習できるようにしようとしう仕組みです。
実験結果
セグメンテーションのアノテーションを自前で作成するのはなかなか大変なので,今回はベンチマークによく用いられるNYU Depth Dataset V2とCityscapes datasetを用いました。
結果を見れば分かりますが,NYUD-v2の方は室内で撮影した画像,Cityscapesはドライブレコーダー的な画像になっています。
という訳でまずはNYUD-v2です。


細かいところはズレてますけど,概ねちゃんと学習できているようには見えますね。少なくともセグメンテーションにおいてPSPNetはちゃんと機能するネットワークとは言えるようです。
次にCityscapesの結果です。
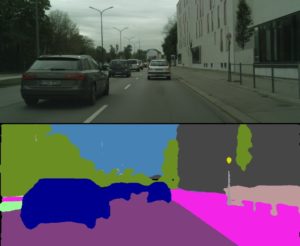

こんな感じになりました。こっちもある程度特徴を捉えられているようには見えますので,データセットに依らずPSPNetはある程度は有効なようです。
まとめ
という訳で今回はPSPNetでのセグメンテーションをやってみました。3クラス以上のセグメンテーションをやってみるのは初めてだったので上手く学習できるか若干不安ではありましたが,やってみると意外と出来ているようです。
物体検出とは違って自前のデータでのアノテーションを作るのが面倒なので,オリジナル画像でテストしてみることが出来ないのは残念ですが,とりあえず勉強にはなったので良しとします。
ということでセグメンテーションのやってみた緩い記事は以上になります。