今回は珍しくIT関連の記事です。
技術的に詳しく書くというよりは「こんなことやってみましたー」的なノリで日本語ベースで書いているので,コードレベルで詳しく知りたい方にとっては参考になる情報はないと思います。

Deep Learning (DL,深層学習)ってなんじゃらほいっていうような人はそもそもこの記事を開くところまでいかないと思いますので,Deep Learningについての説明はしません。
もしどういうものか知りたい人は,ググってもらったらやさしい説明が沢山出てくると思います。
Deep Learningというのは超スーパーざっくりいうと上の画像みたいなやつです。
ちなみにソースはGitHubにありますので,もしよければ参考にしてください。
Deep Learningをやってみたきっかけ
最近仕事が結構しんどい状況だったのですが,それも無事なんとか収束して,1週間ほど急遽夏休みとなりました。
ただ,本当に急に決まったことと,ちょうど夏休み中に台風が来たりしていて,ロードバイクに乗りに行くこともあまりできない,何とも寂しい夏休みになることになりました。
去年もちょうど夏休みのタイミングで台風だったんだよなぁ…。
そんな不幸な夏休みでしたので,家に引きこもってちょっとまじめにDeep Learningの勉強なんかをしてみました。
ちなみに,直前までしんどかった仕事というのがまさにDeep Learning関連の仕事でした。
その仕事の中でDeep Learningを使って顔検出を本当はやりたかったんですけど,Deep Learningでやる時間もなく,しかもデータも無くという感じで結局顔検出は諦めたので,今回不幸な夏休みの時間を使って,そのリベンジを果たそう的なモチベーションもあります。
やりたかったこと/実際にやったこと
やりたかったことはタイトルから分かる通り「顔検出」です。
もう少しちゃんというと,1枚の画像があったときに,顔があればその位置を検出したいということです。
こういうイメージですね。

ちなみに画像は最近ドラマや映画でよく見る石川県出身の浜辺美波さんです。
地元民なのでめっちゃ応援してます!
そういう訳でこういうことをやろうと思っていました,最初は。
パッと思いつくやり方としては,画像を入力したときに,顔の位置を表す矩形(上の赤い四角)の座標や幅・高さを出力するというようなやり方かと思います。
ただ,いざやろうとしたときに「顔が複数ある場合はどうするんだ…?」という問題に行き当たりまして…。
Faster-RCNNとかを勉強していい感じの手法を使えば複数検出も簡単に出来るのでしょうが,そこまではまだちょっとスキルが追いついていないということと,まずはサクッと手を付けてとりあえず動くものを作りたいということがありました。
そのため,独自に別のやり方を考えることにします。
結局こうやった
じゃあどうやるんだというところで少し考えていたところ,「顔があるところは1,無いところは0を出力するような仕組みにすればいいじゃん」というところに行きつきました。
ざっくり↓こんなイメージです。
<入力画像>

<出力結果>

※上の画像はイメージなので出力結果を白黒にしていますが,実際には黒部分は0,白部分は1となるようにします。
こんな感じでやれば,画像の中でどの辺が顔なのか,もしくは顔じゃないのかという判別くらいはできるんじゃないかと思います。
という訳で,やりたかったことは顔位置の座標を出力するようなものでしたが,手間とか時間とかスキルとかを考慮して,実際にやったことは以下のようなものです。
- 入力は画像
- 出力は各ピクセルが顔(の一部)なのか違うのかを[0, 1](0~1の閉区間)で表した値
実行環境
まずは箇条書きでザっと書きます。
- GPU環境
- GPU付属版のSurface Book
- Requirement
- Python3.6
- Keras==2.1.4
- TensorFlow(GPU)==1.4.0
Deep Learningをやってみる上で,需要になるのがご存知GPUです。
今回は,たまたま手元にあったというか,いずれDeep Learningの勉強にも使えるようにと購入していた,初代Surface BookのGPU付属バージョンでやってみました。
本当は最低でもゲーミングPC程度のGPUを使った方がいいんだろうと思いますが,色々費用的な問題とか家計的な問題とかお財布的な問題とかで,手元にあるGPUマシンということでSurface Bookになりました。
ちなみに,このGPUのメモリは1GB程度になっていまして,ネットワークを大きくし過ぎるとメモリが足りなくなって落ちます…。
Deep Learningを少しでも勉強してことがある人なら分かると思いますが,ネットワークが大きいと,重みの数がめちゃんこ多くなっていきます。
重みって何か分からない人向けにいうと,この記事の一番上にあるネットワークっぽい図の中で,〇と〇をつないでいる線のことです。
図を見てもらえば分かる通り,〇が大量に増えていくと倍々ゲームで一気に線が増えていくことが分かると思います。
そうすると,もうデータ量が大きくなりすぎてそもそもネットワークのデータ自体がメモリに乗りきらなくなってエラーになってしまいます。
そのため,本当はVGG16とかある程度の規模のネットワーク構造にしたかったのですが,小さめの自作ネットワークになりました。
VGG16の雰囲気だけは踏襲していますが。
※後々気付いたのですが,使うデータによってネットワークが多少大きくても落ちたり落ちなかったりしていて,ちょっと落ちる条件がよく分からなくなってきましたので,この落ちる話は参考程度にお考え下さい。
使用データ
顔検出用のデータはググればいくつかすぐに出てくると思いますので,好きなものを使えばいいと思います。
今回はWIDER FACEというのを利用しました。
これの [Download] – [Wider Face Training Images] をダウンロードしてきて,上に書いたような形式のデータに変換しました。
画像の枚数はたしか1万枚程度だったかと思います。
※もし商用利用を考えている場合は,ライセンスの問題がないかなどは各自の責任でご確認ください。
なお,先にも書いたようにメモリの問題がありましたので,画像のサイズは入力も出力も128×128ピクセルに変換しています。
ネットワーク構成
まだ色々いじっている状況ではありますが,この記事を書いている時点ではこのような構成にしています。
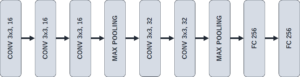
本当はチャネル数をもっと増やして,層数も増やして,Full Connection層のユニット数も増やしたかったのですが,如何せんメモリが残念すぎるので…。
ちなみにメモリが足りないと学習を実行してすぐに「ResourceExhaustedError」ってのが出てきます。
何回も続くと結構イラっとします。
<追記>
少しアップデートしまして,今の状況はこういう構成になっています。

ミニバッチのサイズとネットワークの層数のギリギリを見計らって,この構成に落ち着きました。
結果
夏休みの初日から始めて1週間ほど色々手探り状態で試行錯誤してきて,最新の結果がこんな感じです。






画像内に顔がひとつだと比較的ちゃんと検出されているのが分かりますね。
3枚目の2人の画像なんかはデータの加工方法やネットワーク構造によってうまく検出できたりしなかったりという感じですね。
5枚目とか6枚目辺りの顔の数が多い画像は,最初は全然検出できなくて泣きそうだったのですが,複数の顔が映っている画像を学習データに増やすとある程度検出してくれそうな傾向は出てきました。
<追記>
アップデートしたネットワークでの結果はこんな感じです。
多少は良くなったかなと思います。
ついでに,まだ微調整の余地はありますが,矩形を求めるアルゴリズムも追加してみました。
矩形を描けると何か顔検出やってるっていう感じになってきました!






まとめ
色々試行錯誤していて気付いたのは大きく以下の3点でした。
- ハイパーパラメータをいじるのは大して効果がない。だいたいAdamのデフォルト設定値とかでOK。探索するにしても最後の悪あがき用
- うまく検出できないケースがあるときは,その検出できないケースを同じような画像を学習データに加える,基本的にはEnd2Endの考え方(複数の顔がある場合に検出できないのであれば,複数の顔がある画像を学習データに加えるなど)
- ネットワークは基本的には深い方がいい傾向がある(低スペックGPUが原因であまり深いネットワークを作れなくて,結果的に1層当たりの影響が大きかったということもあると思いますが)
精度を上げていくうえで重要なのは,まずは学習データ,そしてネットワークの深さ,最後のあがきでハイパーパラメータをいじってみるという感じでしょうか
以上,顔検出というのは比較的初級者向けのテーマだとは思いますが,多少なりとも結果が出てくれたので記事にまとめてみました。
Deep Learningをやってみた的な記事は沢山ありますが,肝心の学習データ(特にラベルになるデータ)の作り方とか,どういう方針でチューニングをしたのがといったことを書いてくれている記事は意外となかったりするので,その辺も書いてみました。
まぁデータの作り方はかなり重要な部分なので,詳しく書けなかったり書きたくなかったりという人が多いんだとは思いますが…。