ディープラーニングを使っているとよく遭遇する”データがメモリに乗り切らない”問題についてです。全データを一気に読み込むのではなくて,逐次的に読み込んでいく方法です。
今回は画像データを取り扱う場合を例に説明していきます。
課題の設定
いきなり実装方法を書いても分かりにくいと思いますので,まずはどういうデータを使ってどんな学習をさせるかを簡単に確認しておきます。
学習させる内容
- 画像データを入力して,各ピクセルごとに”顔”である確率を出力する
- 大量の画像データ(JPEG)を読み込む場合を想定
- 教師データは以下の通り
- 顔座標を表すデータは最初にすべて読み込む
- データ加工は画像の読み込みと同様に逐次的にパイプライン処理を行う
入力データ例
このような画像を入力にします。今回はデータの前処理の例として,リサイズして使用することにします(ファイル名:image_000001.jpg)。

教師データ例
上記の入力データに対応する,加工前の元になる教師データです。画像内に3つの顔がありますので,それぞれの顔の位置を表す座標データになっています。
[
{
"FileName": "image_000001.jpg",
"BBox": [
{
"Left": 578,
"Top": 90,
"Width": 142,
"Height": 202
},
{
"Left": 464,
"Top": 346,
"Width": 126,
"Height": 146
},
{
"Left": 218,
"Top": 186,
"Width": 128,
"Height": 170
}
]
},
... Other images' FileName and BBox data ...
]
このデータを処理として,最終的に次のようなイメージの “0” or “1” の2次元行列に変換したものを教師データにします。
- 白:顔のピクセルを表す(実際のデータの値は1)
- 黒:顔以外のピクセルを表す(実際のデータの値は0)
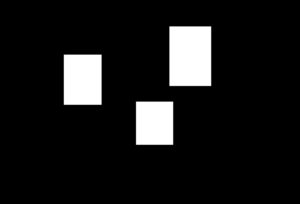
実装方法
全体的な処理の流れ
- 画像ファイル名のリストと顔座標データのリストを用意する(①)
- torch.utils.data.Datasetを継承して,①のリストを持つためのDatasetクラスを作成する(②)
- データの前処理を行うクラスを作成する(③)
- Rescale:リサイズ処理(任意)
- ConvertGroundTruth:教師データの加工処理(今回の課題設定では必須)
- ToTensor:PyTorch用のTensorに変換する処理(必須)
- ②と③から作成したDatasetインスタンスと,torch.utils.data.DataLoaderから,DataLoaderインスタンスを作成する
1. リストの準備
まずは画像のPath(files_train, files_test)と教師データの座標(labels_train, labels_test)をそれぞれリストで取得します。
ポイントは画像は読み込まずに,画像ファイルのPathだけを保持しておくことです。今回は教師データはもう座標データとして読み込んでいますが,もしサイズが大きいようでしたらこちらも同様にPathだけ保持しておいて,画像と同様に後続処理で逐次読み込むようにします。
import json, Path
from sklearn.model_selection import train_test_split
input_dir = '/PATH/TO/IMAGE/DIRECTORY'
bbox_json = 'bbox.json'
with open(bbox_json, encoding='UTF-8') as f:
bboxes = json.load(f)
files = []
labels = []
for bbox in bboxes:
files.append(Path(input_dir).joinpath(bbox['FileName']))
labels.append(bbox['BBox'])
files_train, files_test, labels_train, labels_test = train_test_split(files, labels, test_size=test_size, random_state=0)
※bbox.jsonは”教師データ例”で示したJSON形式のデータです。
2. Datasetクラスの作成
torch.utils.data.Datasetを継承して,以下のメソッドを作ります。
- __init__:画像ファイルのPathと教師データのリストを受け取る
- __len__:リストの長さを返す
- __getitem__:読み込んだ画像と教師データをディクショナリで返す(前処理を実施する場合は,後述するtransformで実施)
from skimage import io
class BatchDataset(torch.utils.data.Dataset):
def __init__(self, files, labels, transform=None):
"""
Args:
files: List of image file names (Paths to image).
labels: List of ground truth.
Note:
The orders of 'files' and 'labels' must match.
"""
self.files = files
self.labels = labels
self.transform = transform
def __len__(self):
return len(self.files)
def __getitem__(self, idx):
img = io.imread(self.files[idx])
label = self.labels[idx]
sample = {'image': img, 'labels': label}
if self.transform:
sample = self.transform(sample)
return sample
3. 前処理用のクラスを作成
ここでは3種類のクラスを作成します。
- 入力画像をリサイズして,すべて同じサイズの画像に変換するクラス
- 入力画像のリサイズに合わせて,教師データの座標も変換します
- このクラスは今回の問題設定のための処理なので,適宜削除したり別の任意の処理に置き換える等してください
- 教師データの加工を行うクラス
- これも今回の問題設定に合わせるための処理なので,消すなり改変するなり自由にしてください
- PyTorch用のTensorに変換するクラス
- これはPyTorchのお作法として必要なクラスです(わざわざ独立したクラスにする必要はありませんが)
3-1. Rescale(画像サイズと座標の変換)
画像を読み込んだデータを指定のサイズにリサイズして,そのサイズに合わせて教師データの座標も変換します。
import cv2
class Rescale(object):
"""
Rescale the image in a sample to a given size.
Args:
output_size: Desired output size of tuple.
"""
def __init__(self, output_size):
assert isinstance(output_size, tuple)
self.output_size = output_size
def __call__(self, sample):
img, labels = sample['image'], sample['labels']
# Rescale image
h, w = img.shape[:2]
new_h, new_w = map(int, self.output_size)
img = cv2.resize(img, (new_w, new_h))
# Rescale ground truth
rescaled_labels = []
for label in labels:
rescaled_label = {}
rescaled_label['Left'] = int(label['Left'] * new_w / w)
rescaled_label['Top'] = int(label['Top'] * new_h / h)
rescaled_label['Width'] = int(label['Width'] * new_w / w)
rescaled_label['Height'] = int(label['Height'] * new_h / h)
rescaled_labels.append(rescaled_label)
return {'image': img, 'labels': rescaled_labels}
3-2. ConvertGroundTruth(教師データの作成)
今回の問題設定の場合,教師データは最終的には2次元の形式にする必要があるため,ここでその変換を行います。
import numpy as np
class ConvertGroundTruth(object):
"""
Transform ground truth data from rectangle axes to one binary map.
Args:
output_size: Desired output size.
"""
def __init__(self, output_size):
assert isinstance(output_size, tuple)
self.output_size = output_size
def __call__(self, sample):
img, labels = sample['image'], sample['labels']
h, w = map(int, self.output_size)
output_map = np.zeros(h * w).reshape(h, w)
for label in labels:
left = label['Left']
top = label['Top']
width = label['Width']
height = label['Height']
output_map[top:top+height+1, left:left+width+1] = 1.
return {'image': img, 'labels': output_map.flatten()}
3-3. ToTensor(データ構造の変換)
PyTorchは最終的にデータをTesorに変換する必要があるため,そのためのクラスを作成します。
class ToTensor(object):
"""
Convert ndarrays in sample to Tensors.
"""
def __call__(self, sample):
img, labels = sample['image'], sample['labels']
# Swap channel axis
# numpy image: Height x Width x Channel
# torch image: Channel x Height x Width
img = img.transpose((2, 0, 1))
return {'image': torch.from_numpy(img), 'labels': torch.from_numpy(labels)}
4. DataLoaderの作成
ここまでで作成してきたものを使って,DataLoaderインスタンスを作成します。前処理はtransforms.Composeを使ってパイプライン処理として設定します。
from torchvision import transforms
train_dataset = BatchDataset(
files=files_train,
labels=labels_train,
transform=transforms.Compose([
Rescale(rescale_size),
ConvertGroundTruth(rescale_size),
ToTensor()
])
)
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset,
batch_size=32,
shuffle=True,
num_workers=4
)
ここまででDataLoader(train_loader)が作成できましたので,後は通常通りに学習させていけば良いです。